国家自然科学基金项目结题成果科普性介绍——微处理器敏捷设计方法关键技术研究
本项目来源于国家自然科学基金区域创新联合发展基金项目“微处理器敏捷设计方法关键技术研究(No. U19A2062)”,起止时间 2020.1-2023.12。本项目工作概括如下。
一、 主要研究内容
针对微处理器敏捷设计方法的关键科学问题和应用方法开展研究,突破微处理器敏捷设计方法理论与关键技术,包括前端设计建模、微处理器自动生成、设计验证、前端和后端各阶段数据采集和特征提取方法、基于机器学习的后端预测与优化技术,构建前后端设计一体化框架等。将构建的前后端EDA工具链,应用于实际微处理器设计实践,突破微处理器敏捷设计应用方法。提出并构建微处理器敏捷设计方法学及其支撑EDA工具集。
本项目主要研究内容可概括为“一个方法学”和“一套EDA工具链”,如图1所示。
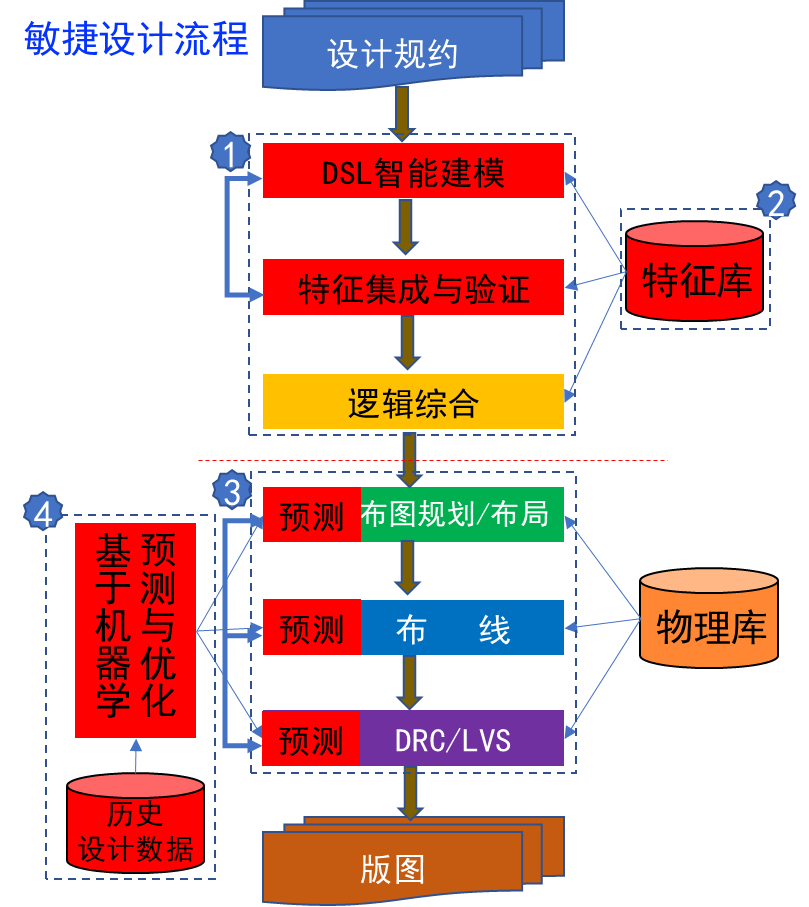
图1 项目主要研究内容
研究内容共涉及到4个环节,首先,项目将依托现有设计流程开展微处理器敏捷设计关键技术的研究。其次在RTL设计建模、设计验证、设计库等环节,通过提升设计建模的描述能力,以支持更广泛的设计重用、更灵活的设计修改、支持基于特征集成的快速设计集成、快速生成微处理器设计的设计探索,以及基于特征的快速验证方法,来加速前端设计的快速设计迭代。第三,引入基于机器学习的预测与优化方法,通过前后端无缝数据收集与共享,对底层设计环节进行基于机器学习的设计预测和优化增强,以减少人工干预,加快设计迭代。第四,通过前后端无缝数据的集成,支持EDA工具的快速重构适配。
二、研究方法与研究结果
2.1 微处理器敏捷设计前端设计、建模与优化方法
进入后摩尔时代后,登纳德缩放定律和摩尔定律走向终结,微处理器设计和架构的新方法变得越来越重要,需要领域特定体系结构(domain specific architecture,DSA)和新的开发方法,来快速生成针对不同应用需求的高效专用芯片[2]。因此,集成电路设计领域也将面临应用需求不断变化、快速应对应用需求和芯片上市时间等压力。芯片设计方法对提高微处理器设计效率的重要性越来越高。与软件开发领域相比,将敏捷设计方法应用于微处理器设计已成为一种可选的解决方法。
可以在软件设计方法中找到对这种多特征同时集成与探索的类比场景—面向特征编程(Feature Oriented Programming,FOP)方法。FOP是在面向对象编程方法之上的一种软件开发方法。其核心思想是将软件分解为更小的块(称为特征),并根据用户的需求进行组合。FOP 称对象在特征实现中所起的作用为角色(role)。特征模块与对象之间往往是一种正交关系,应用程序的对象通常同时参与多个特征的实现,每个特征的实现通常依赖多个角色之间的合作,因此一个对象可能编码几个不同的角色。通常,一系列的特征组成一个最终的程序,这个程序本身就是一个特征。这样,一个特征既可以是一个可以执行的完整程序,也可以是一个需要进一步组合其它特征才能形成完整程序的程序增量。
遵循微处理器敏捷设计方法的研究成果,项目基于PyRTL语言开展该方法学落地研究,具体为基于PyRTL的FOP建模方法支撑机制的设计与实现,包括设计描述、特征建模、特征集成等,基于等价饱和的组合后设计优化技术,以及基于模糊测试方法的验证技术。
2.1.1 基于PyRTL的FOP设计建模
为支持面向特征编程,我们从两个方面对PyRTL进行了扩展。一方面是扩展Python以支持FOP在语法和语义上的建模。另一方面是实时合成算法。
首先,仍以PyRTL提供的各种RTL建模机制来建模特征模块,且每个特征模块用面向对象方法进行设计与描述。其次,定义了一些机制来帮助设计人员灵活地建模和组合功能,以增加设计的可重用性。具体实现上,在语法上将“+”操作符定义为“合成”(“·”)操作符。在语义上重载PyRTLBlock类的__add__方法来返回组成电路的Block。因此,特征组合公式P=C·B·A可以表示为P=A+B+C。
第三,进一步重载PyRTLBlock类中的__getattr__方法。因此,设计者可以使用信号的名称直接从模块中选择相应的信号。最后,在Block类中增加了一个新的input_circuit方法,将设计细化到PyRTLIR块中,使我们的组合算法能够实时生成组合设计。
2.1.2 基于等价饱和技术的设计优化技术
由于FIRRTL应用较广,且成为事实上的标准,而PyRTL IR可等价自动地转换为FIRRTL,因此,本项目中对组合后设计的优化是在FIRRTL格式上进行的。
项目提出一种基于等价饱和的FIRRTL优化方法。该方法首先从输入的FIRRTL文件创建初始的等价图(E-Graph),然后利用等价饱和引擎不断运行一组重写规则,直到E-Graph达到饱和。接下来,提取算法会根据给定的 开销模型选择最优的子图,最后,将优化后的子图写回FIRRTL。
直观来说,基于等价饱和的优化技术,是将所有可能的等价的优化都枚举出来,并记录所有这些等价优化的中间结果。最后,基于优化目标函数,扫描一遍所有的优化中间结果,得到最优化的函数解,该解对应的优化中间结果组合成的设计,即为最优的优化设计。
2.1.3 基于模糊测试的设计验证方法
针对目前基于模糊测试方法的不足,本项目在种子输入生成、变异策略选择、覆盖率测度等方面进行了改进:
-
覆盖率测度方面:选择多路选择器,特别是2-1选择器的控制信号作为覆盖率目标。我们通过定义全选择器跳变覆盖率(Full Multiplexer Toggle Coverage,FMTC)来等效地实现对电路中控制信号的覆盖。FMTC定义为多路选择器在一次测试中,其控制信号值应从0切换到1再切换到0,或从1切换到0再切换到1。此外,定义了断言覆盖率,以体现对功能覆盖的度量。
-
在种子输入生成方面:根据被测器件的电路结构产生种子输入。计算每个多路选择器的影响锥(Cone-of-Influence,COI)。然后,选择具有最大COI集的复用器,并使用符号模拟和约束求解技术生成能够覆盖所选复用器的测试。生成的测试作为种子输入来启动测试过程。
-
变异策略选择技术:项目中面向数字电路位向量运算的特点,针对性地实现了AFL中常用的确定性变异和非确定性变异算子。在变异算子和种子输入的选择上,提出了基于马尔科夫链的变异算子选择策略,根据测试反馈,预测并选择能到达更多新覆盖的变异算子和种子输入。
2.1.4 研究结果
研究取得的成果通过在典型微处理器设计上的应用及评估得到验证。首先,以RISC-V和OpenRISC1200两个典型微处理器作为实验案例,评估基于FOP的微处理器敏捷建模方法的有效性。OR1200是一个32位RISC处理器,具有五级流水线。
对比OOP、FOP和直接修改代码三种增量式设计方法的时间开销,可以看出FOP方法相比于其他方法,随着新增指令或指令类型的增加,设计效率显著提升。
表1 OOP、FOP与直接修改代码三种方法的设计效率
其次,评估了本项目设计优化算法的效率,结果如表2所示。评估过程首先利用PyRTL 提供的转化接口将组合的特征模块的中间格式转化为FIRRTL文件。其次,在此基础上生成对应的Verilog文件送入yosys进行逻辑综合得到实际的逻辑单元数,结果如表中第3列所列。同时,将该FIRRTL文件运用框架中的等价饱和优化模块进行优化,与上述类似,生成对应的Verilog文件送入yosys进行逻辑综合得到实际的逻辑单元数,结果如表中第4列所列。表中最后1列给出了基于等价饱和优化方法与FIRRTL库原生的优化方法,在单元数节约上的节约率。
表2 设计优化效果
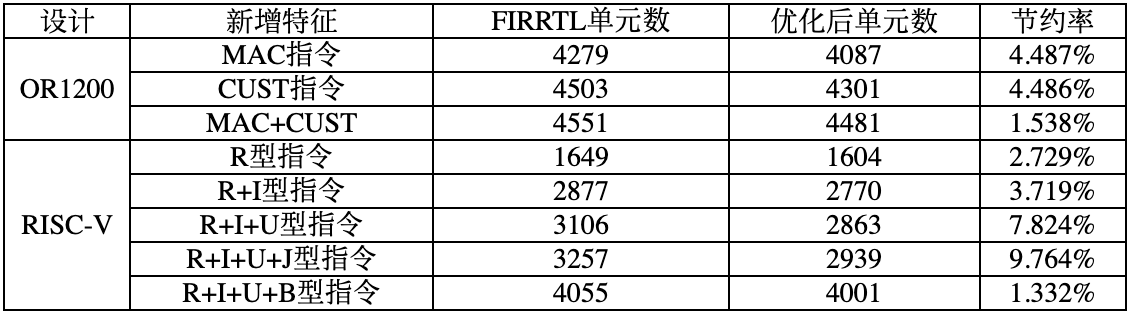
从表中数据可以看出,基于等价饱和的优化方法可以有效降低面向特征的设计的硬件开销,一些设计的优化效果可以达到 9.764%。
最后是基于马尔科夫链的微处理器模糊测试方法的评估,我们采用了分别在RFUZZ和MPFUZZ中提出的(Mux Toggle Coverage)MTC和(Full Multiplexer Toggle Coverage)FMTC覆盖度量。这两个覆盖率评价标准广泛用于HDSL相关模糊测试工具的覆盖收集。为了实现MTC,多路复用器的控制信号值需要实现0-1或1-0跳转,而为了实现FMTC,多路复用器的控制信号值需要实现0-1-0或1-0-1跳转。
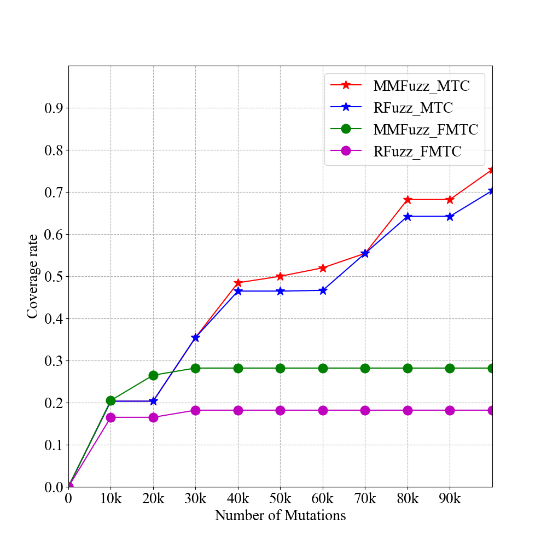
图2 OpenRISC1200测试结果
图2与图3展示了基于马尔科夫链的微处理器模糊测试方法与RFUZZ工具,分别在OpenRISC与RocketChip两个典型微处理器设计上,在两个不同覆盖标准上的结果对比,其中星型标记的折线评价在MTC标准上的结果,红色线条代表本文工具,蓝色代表RFUZZ工具;圆型标记的折现评价在FMTC标准上的结果,绿色线条代表本项目工具,紫色线条代表RFUZZ工具。
从图中得出初步结论,对于两种不同的覆盖标准,在相同的突变次数下,基于马尔科夫链的微处理器模糊测试方法可以获得比RFUZZ更高的覆盖。由于在FMTC覆盖标准中,在单次测试中需要比在MTC覆盖标准中多实现一个信号切换,所以在所有测试用例中,这两种工具在FMTC覆盖标准上的结果比在MTC覆盖标准上表现更差。
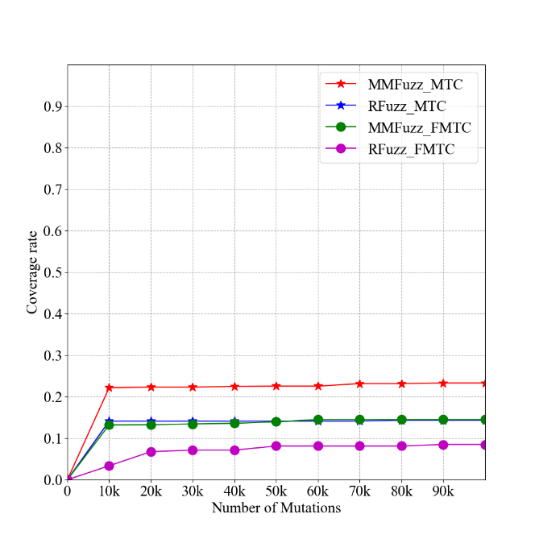
图3 RocketCore测试结果
2.2 结合机器学习的微处理器敏捷设计后端设计与优化方法
敏捷设计的主要目标是实现无人参与的设计自动化,因此需要依靠各设计阶段性能的准确预测来有效地指导各个阶段的设计优化,尽可能减少人工干预以及设计的返工迭代。在芯片RTL-to-GDSII设计流程中,敏捷设计方法需要广泛借助机器学习技术,寻求“无人参与”的解决方案。时序性能作为芯片的重要性能指标,在RTL-to-GDSII设计的各个流程中均需要进行静态时序分析。快速、准确和可靠的时序预测,可以将签核(Sign-Off)阶段的时序性能前馈到早期设计流程中,指导早期设计的时序优化和时序收敛,减少芯片设计的迭代次数,缩短迭代周期。
为了帮助提高RTL-to-GDSII流程中性能预测与Sign-Off时序分析结果的一致性,本项目后端主要针对时序性能采用基于机器学习的时序预测方法,并探索指导RTL-to-GDSII流程中布局阶段结合时序预测的优化过程。此外,为了使上层体系结构设计方案得到及时反馈,需要对上层体系结构各个硬件对象的特征参数进行RTL-to-GDSII各个阶段的设计跟踪,所得数据可以作为评估设计方案的依据。
2.2.1 后端设计的数据体系构建
对于主要设计流程如图所示,以微处理器RISC-V CVA6为例,包括:综合、布局、时钟树综合、布线、时序分析和功耗分析工具、实际工业界设计原型验证等指标,给智能化设计提供完备的数据体系。此外,由于不同工艺库、不同PVT工艺角下,数据样本(如逻辑门和连线等),对应的电容电阻值和时序信息是不同的。在提高样本多样性的同时需要进行准确的特征选取,对增加时序预测的普适性和实用性十分重要。
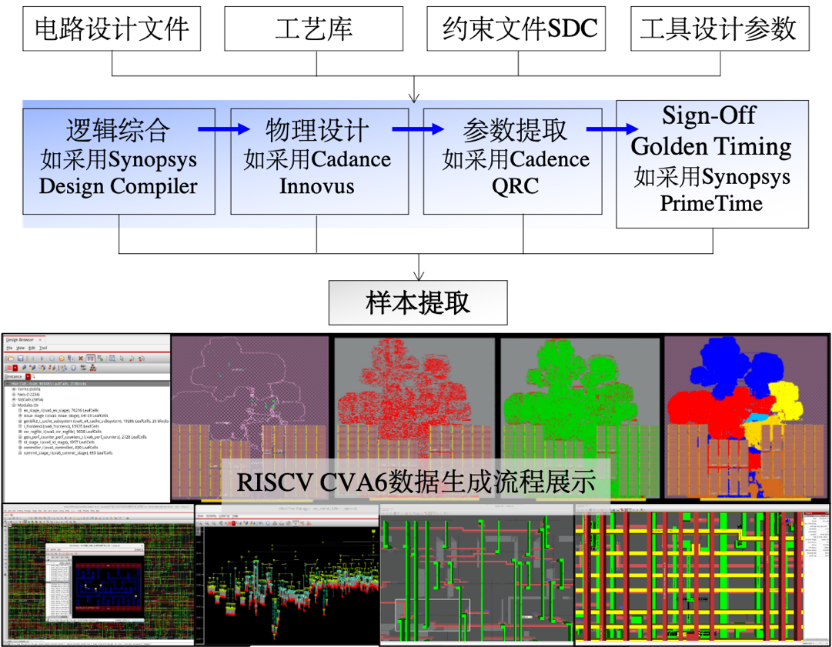
图4 电路数据构建流程
2.2.2 早期关键路径预测模型
为了改善早期设计中过度悲观分析时序性能,提升预测的准确性,减少设计迭代,获得更好的PPA (Power, Performance, Area),引入了机器学习方法。给定工艺库,输入电路网表和其布局结果,以及其对应的Sign-Off时延作为Truth Ground,训练得到可准确预测时延的模型。该模型可为同工艺下,其他电路预测时延。根据预测出的时延信息,通过电路图拓扑遍历,计算出每个节点的Slack。如果寄存器或输出端口,即Flip-Flop / Primary Output的Slack为负,则为关键路径。预测目标是在逻辑综合和物理设计早期,预测关键路径和非关键路径,提升同Sign-Off结果的匹配度。该方法通过使用现有设计数据,来训练时序模型。所得模型可在布局阶段,可为同工艺下的未知设计,提供时序预测。
针对布线前的布局阶段,为了帮助布局时序优化,需要提供准确的时序预测。本项目首先,建立基于机器学习的时延模型,用来计算时延。在时延模型训练阶段,时序特征提取对时序预测起关键作用。由于RC网络(RC Network)是时延计算的依据,而RC Network需要布线后才能进行准确提取,为了在布局阶段,就获得更多与时序相关的特征,除了提取输入布局中的节点距离信息外,我们还进行了快速预布线分析,根据布线分析的结果,得到整个电路RC Network信息。值得一提的是,本方法中的RC Network,区别于实际布线后的Sign-Off RC Network,是根据预布线分析结果所得,仅用于模型特征提取。在时序特征提取后,采用机器学习算法,训练得到电路时延模型。
在模型推理阶段,提取电路的时序特征,把特征输入到训练好的时延模型中,预测时延。最后,根据预测时延,通过拓扑顺序遍历,计算每个电路节点的到达时间。最后,报告终端节点,即FF/Primary Output的Slack,区分非关键路径和关键路径。在同工艺下,该训练模型可用于预测跨电路设计。
在此流程基础上,本项目尝试多种机器学习模型,包括GAT, CNN, 以及决策树等算法,其中决策树以其对表格化数据的适用优势,在对Pin-to-Pin的互连时序上表现更高的准确度。为了进一步将模型嵌入布局优化过程,还探索了可微决策树构建方法。在这项工作中,我们选择Gradient Boosting Machine (GBM)模型。由于常见的GBM方法是不可微的,这在一定程度上限制了它们在布局过程中的时序优化背景下的可用性和适应性。为了解决这个限制,应用了Soft GBM框架,将多个可微分的基础学习器连接成一个连贯的、可微分的系统。可微基本学习器使用多层感知器MLP。该MLP是由不同层组成的现代的前馈神经线网,其至少包括输入层、隐藏层和输出层。MLP的核心依赖于三个基本要素:权重、偏置和激活函数。MLP模型本质上是一个由多个非线性和线性变换组成的函数。重要的是,这些单独的变换中的每一个都是可微的,从而确保整个函数表达式也是可微的。
2.2.3 基于时序性能预测的早期布局设计优化方法
在后端设计中,传统布局方法通常关注单元密度约束下的总布线长度。由于单元位置会影响其线网的信号延迟,为了确保电路性能满足时序要求,将时序考虑纳入布局过程至关重要。时序裕量(Slack)通常用于确定关键时序路径,其被定义为要求到达时序RAT和路径到达时间AT的差值。如果裕量为负则路径到达时序不满足要求。
图5给出了结合时序预测模型的后端布局流程。本质上,适当的净权重应将更高的权重分配给对时序更关键的线网,希望布局引擎将减少这些关键线网的长度,从而减少它们的延迟,以实现更好的整体时序。因此,快速、准确的时序分析引擎对于松弛计算和关键路径的确定至关重要。之前利用可微GBM对线网的延时进行预测,在基于线网权重的布局优化时,还可以利用可微时序模型推导出关键路径中的Driver-Sink互连长度权重设置,并引入伪线网提升关键路径上互连权重。给定训练后的GBM模型,对其函数表达式进行线长求导作为线网权重设置依据。根据模型,我们发现具有弱驱动能力和高负载的长导线将对相同的线长变化表现出更高的时序灵敏度,需要设置更高权重来优化时序关键路径。
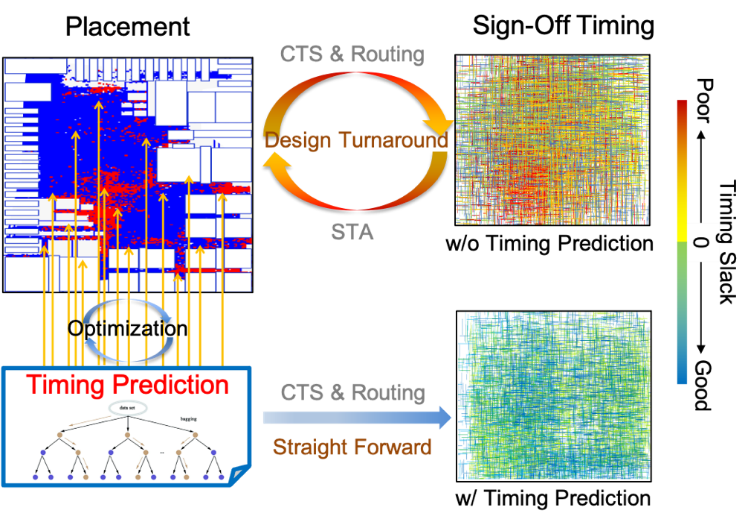
图5 结合时序预测提升布局流程示意图
2.2.4 研究结果
为了证明我们的可微GBM预测模型的有效性,我们首先展示其与传统Elmore延迟进行对比分析。采用的Benchmark如表3所示,包括ITC’99和RISC-V电路。结果显示,与Elmore相比,GBM模型预测结果的Sign-Off相关性有显著改善。此外,平均和最大误差都表现出显着的改善,有效地减少了Elmore延迟的悲观估计。如表4所示,训练模型依赖于CV32E40P和CVA6的50%数据集,在测试集上两个电路的相关度都高于0.9。对于ITC'99的结果,由于其电路规格的变化,观察到预测精度略有下降。
表3 实验用的电路信息
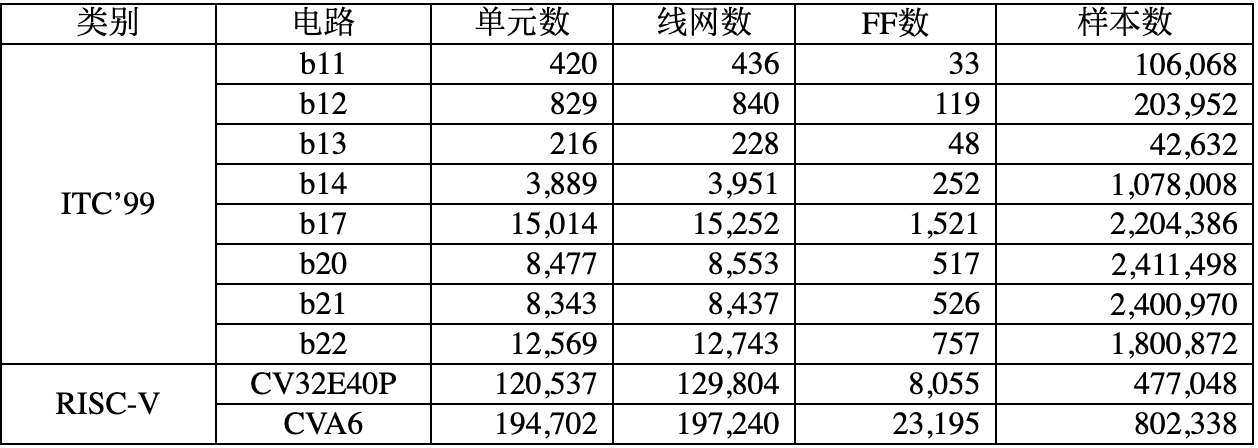
表4 可微线时序模型预测对比
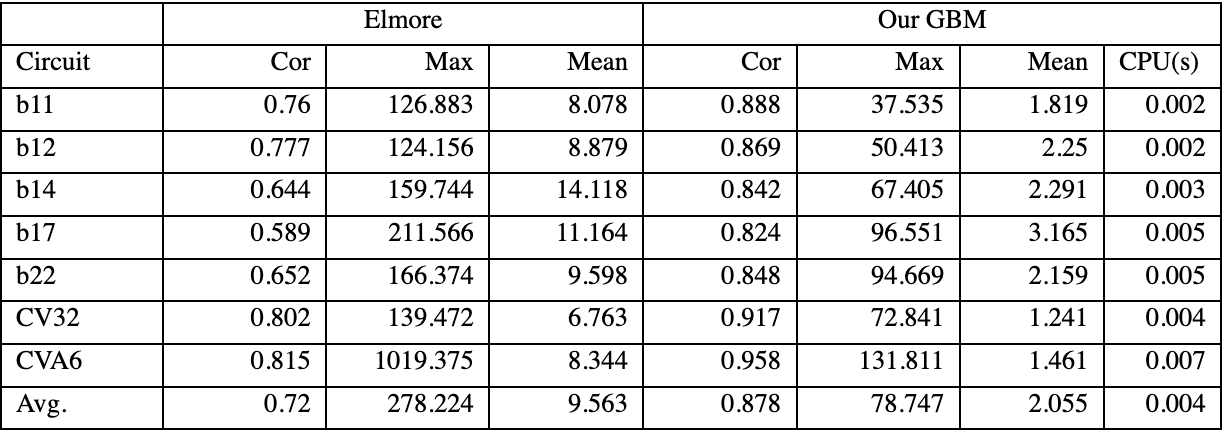
在布局优化过程中,我们采用所获得的可微GBM模型,而不是Elmore 时延的时间评估。利用可微GBM的时序结果,在布局过程中为关键路径互连添加伪网络,并相应地调整网络权重。由于我们的时序优化方法集成到开源工具Dreamplace中,因此我们与开源Dreamplace和基于净加权的时序驱动的Dreamplace 4.0 进行了比较。
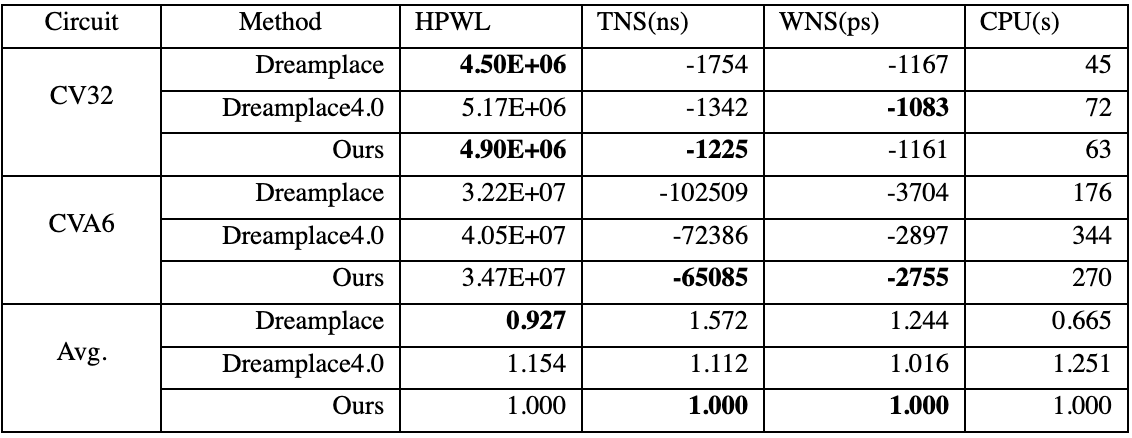
由于ITC'99电路的小规模和相应的太短的线长,通过减少线长来优化时序是不实际的。因此,我们的主要重点是针对较大电路的时序驱动优化,即,CV32E40P和CVA6,如表5所示,平均而言,我们的方法可以分别减少57.2%和24.2%的TNS和WNS。此外,与采用Elmore延迟进行时序评估和净加权优化的Dreamplace 4.0相比,Ours展示了在优化时序的同时实现更短HPWL的能力。这种改进归因于利用更准确的时序预测模型,有效地减轻了由于悲观时序评估导致的过度优化而导致的线长性能损失。
表5 结合时序预测的后端布局结果
三、主要研究成果
经过四年研究,项目提出了基于面向特征编程方法的设计建模方法,提出了基于机器学习辅助的后端设计方法,设计实现了支撑上述2个核心方法的系列EDA原型工具,初步构建了支撑前端敏捷设计建模方法的EDA原型工具集。该工具集在Open RISC及RISC-V上进行了应用,证明了本项目方法及工具的有效性。
项目取得了较好的成果,在国内外顶会顶刊等期刊和会议上共发表论文30篇,申请专利8项,其中4项已授权。依托本项目,培养博士研究生3人、硕士研究12人。项目期间,参与国内外与本项目相关的学术交流活动10次60余人次。